Tutorial
How Finance Teams can extract data from PDFs
November 5, 2025



.svg)

Discover how finance operations teams can streamline workflows by extracting and structuring data from PDFs. Learn the step-by-step process for transforming invoices, statements, and reports into clean, validated, and automated data flows.
How Finance Operations teams can Extract value from PDF documents
In finance operations, documents like invoices, vendor statements, expense reports and contracts often arrive in static PDF form, and staying hands-on with manual data entry means low efficiency, errors, and delayed insights. But by treating PDF extraction as an automated workflow, you turn static files into structured, actionable data.
(The video below shows this process in action.)
1) Extracting text and layout
The first step is getting the raw data out.
Some PDFs are “born digital,” meaning the text can be read directly. Others are scans that require OCR (Optical Character Recognition) to make the text machine-readable.
Either way, simple text extraction isn’t enough: finance documents depend on layout context. The position of an amount next to “Total,” or a date near “Invoice Date,” tells you what that text means.
Traditional scripts or libraries (like Tesseract or PDFMiner) can grab the text, but they lose this layout information. That’s why newer systems pair text extraction with spatial analysis understanding how information is arranged on the page.
2) Understanding and structuring the data
Once you have text and positions, the real challenge starts: structuring.
Most PDFs don’t have a consistent format. One vendor’s “Invoice #” is another’s “Reference ID.” Tables might be neatly drawn, or they might just be aligned text with no borders.
Structuring involves:
- Identifying fields — finding key-value pairs like “Vendor: Acme Ltd.” or “Total: $4,312.50.”
- Reconstructing tables — grouping related lines into rows and columns, even when the layout varies.
- Normalizing schema — mapping all of this into consistent field names and formats (e.g.,
invoice_number,total_amount,currency).
This is the point where many extraction projects stall: You can get text, but not reliable, structured data.
3) Adding context through intelligent mapping
Here’s where AI-driven approaches have made a big difference.
Instead of writing rules for every possible layout, you can describe what each field represents and let the model infer the right patterns.
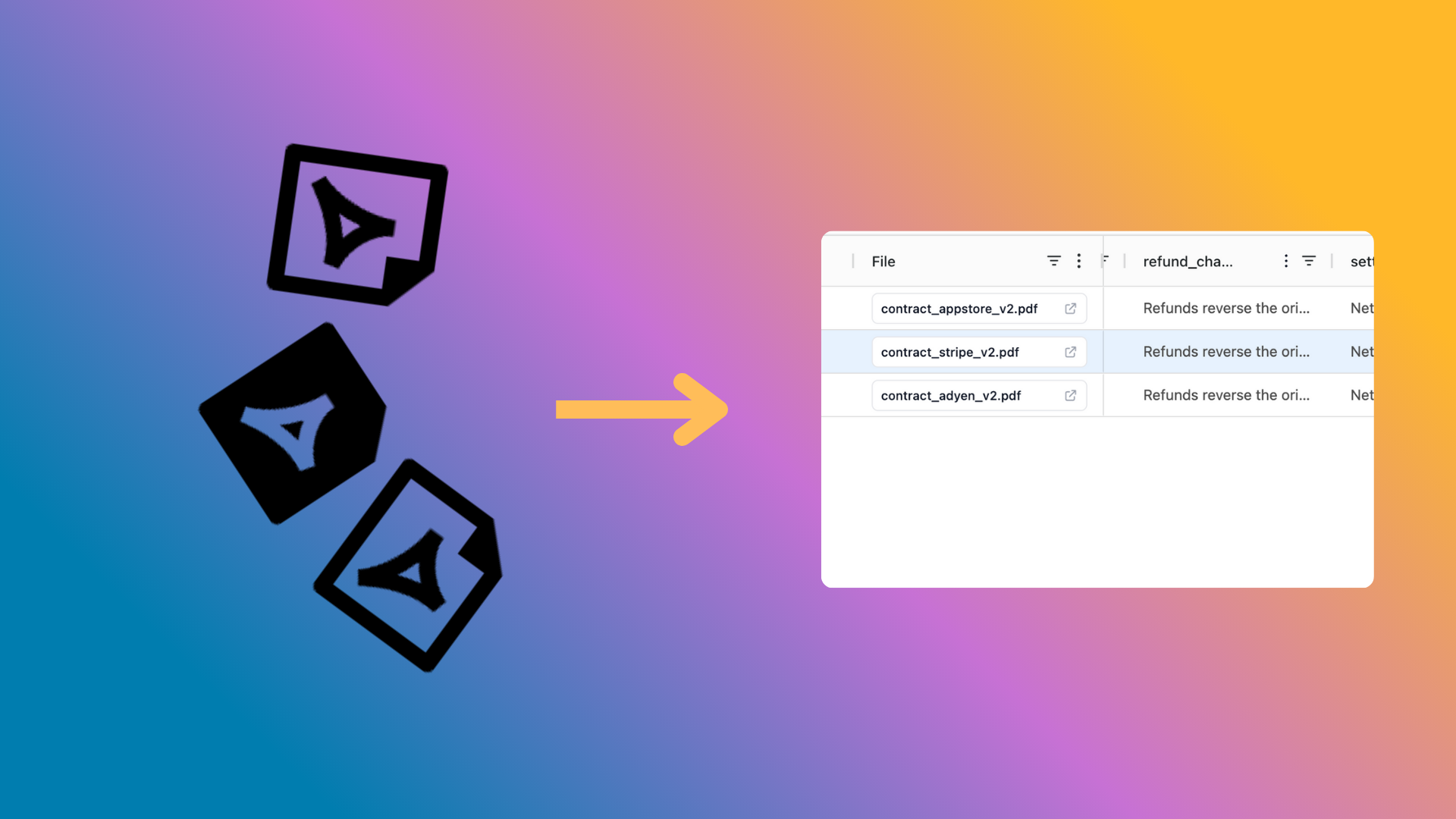
That’s the idea behind cloudsquid’s extraction agents.
You define a simple table of the fields you want, like “Invoice Number,” “Vendor,” “Invoice Date,” or “Total.”
For each column, you write a short instruction (a prompt) describing what to extract, e.g.:
“Extract the invoice number printed near the top right corner of the document.”
Then, the model runs across each PDF, reading the text and layout, and populates your table automatically.
The result isn’t just raw text but rather structured data with bounding boxes in the original document, showing exactly where each value came from.
That visual mapping is key for review and accuracy and you can immediately see if a field was pulled from the right spot.
4) Validating and exporting
Once the data is structured, you can validate it the same way you would in any finance process:
- Check totals against line items.
- Flag missing invoice numbers or duplicate IDs.
- Verify date ranges.
With structured tables in place, exporting is straightforward: To Excel for review, or directly into accounting, ERP, or BI systems for automation.
In cloudsquid, that export step can be connected to downstream workflows, so extracted PDFs automatically feed into your financial logic.
5) Scaling the workflow
After the first setup, the same structure can be reused.
You can apply the same extraction logic to new PDFs, with no templates and no vendor-specific rules, and the model adapts to variations automatically.
For finance teams, this means less manual entry and fewer exceptions to review.
The takeaway
Extracting data from PDFs used to mean wrestling with formats and edge cases.
Now, the process can be defined once: "what fields do we care about, and how should they be read" and then handled automatically at scale.
With cloudsquid you get a clear, auditable, and flexible way to turn documents into structured financial data without rule-writing or manual cleanup.